Instantly deploy production-ready AI clusters and maximize GPU utilization with dynamic scaling and policy-based scheduling.
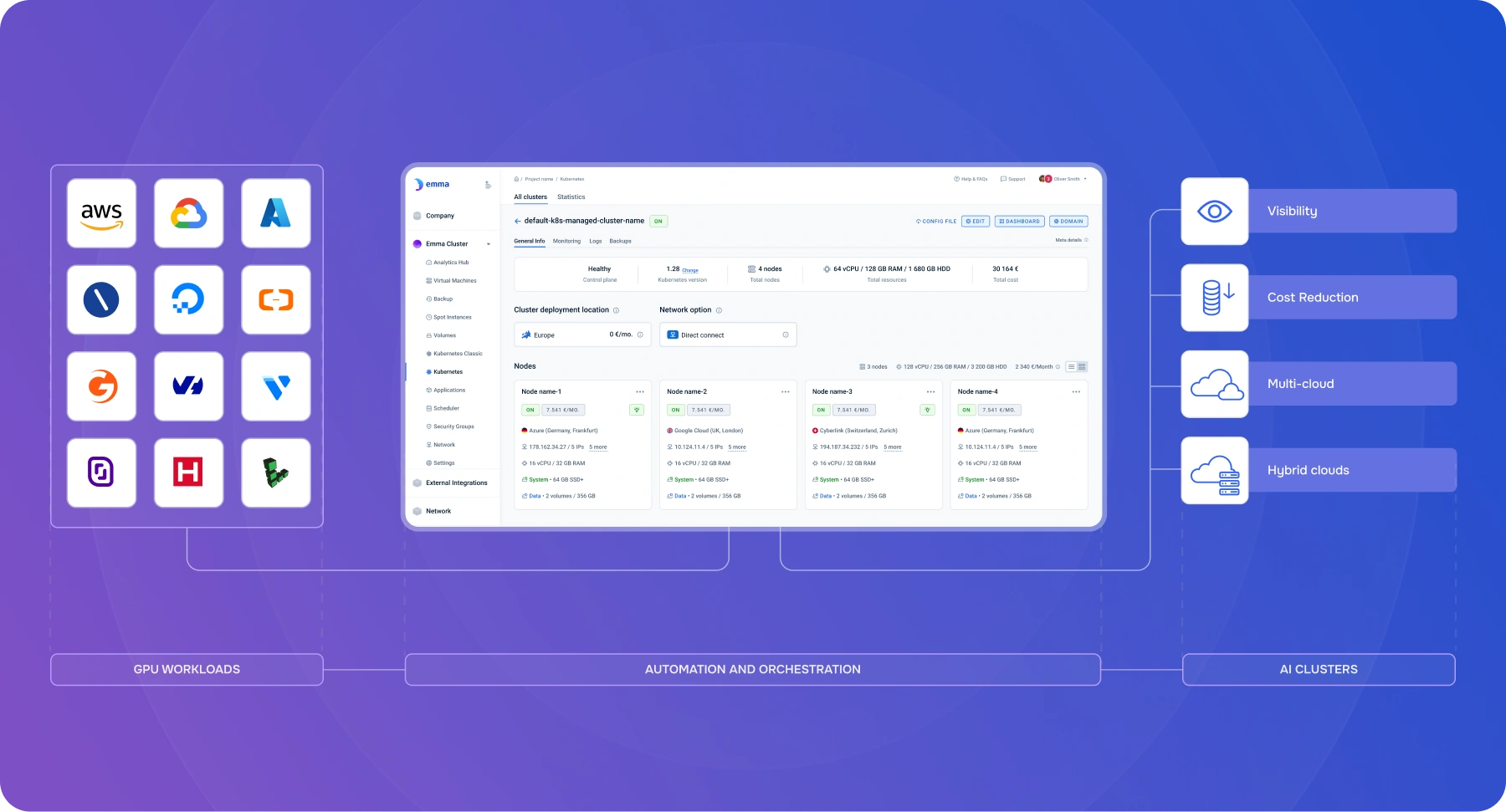
Get a single dashboard to see all your existing and new resources (on-prem and cloud), with full visibility into usage, spend, and ownership.
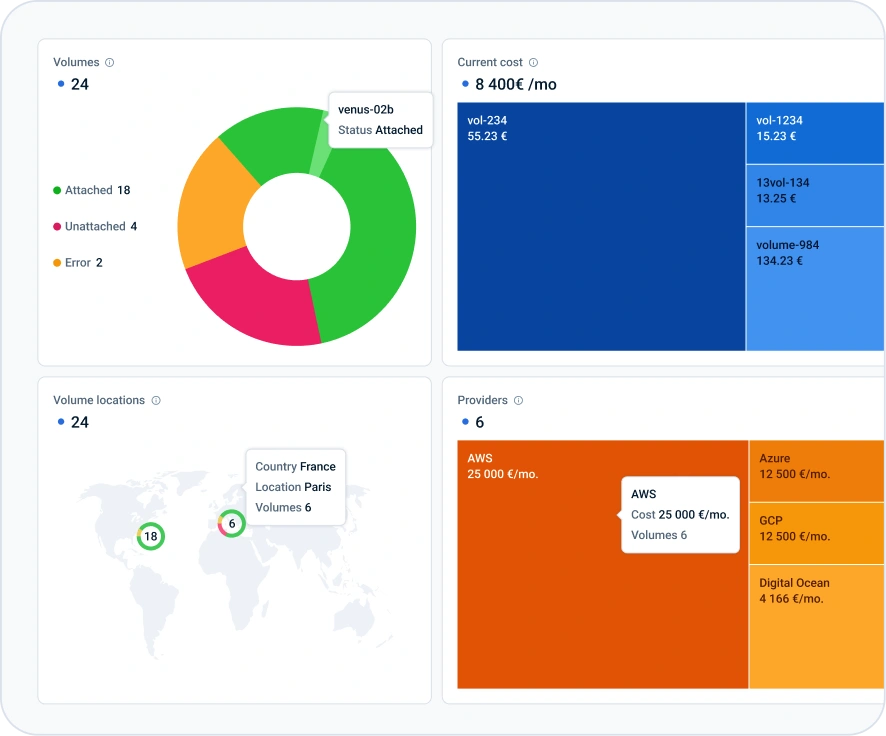
Cut costs for costs of any new or existing clusters (AKS, EKS, GKE) with just a few clicks. Provide project-level cost accounting, showback/chargeback, and budget-tracking to deliver clear ROI metrics.
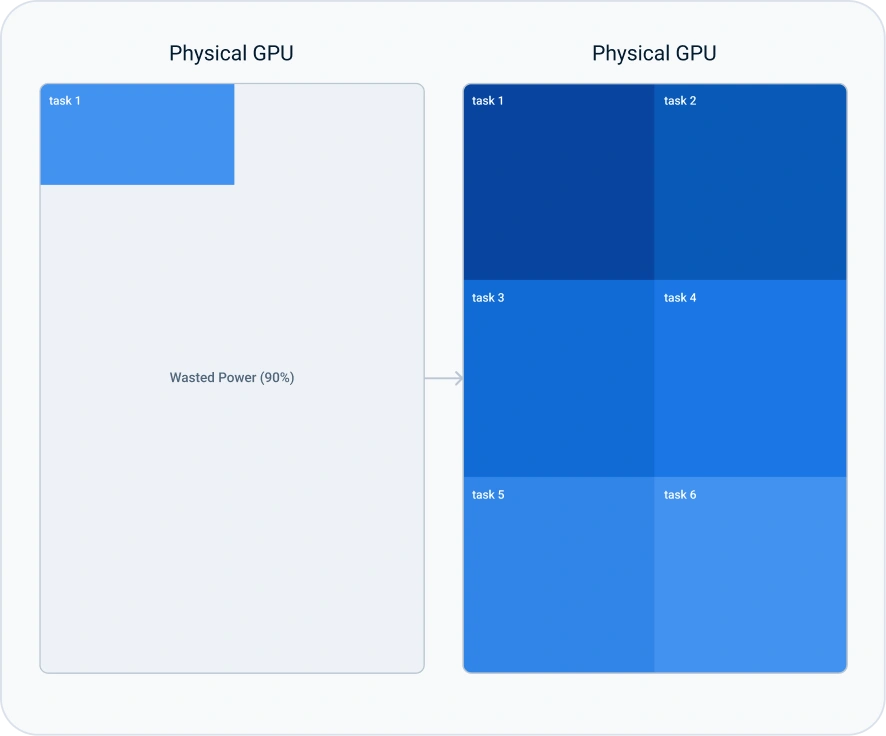
Powerful GPUs often sit idle because many AI/ML jobs (like development or inference) don't use their full capacity. Our GPU fractionalization solution stops this waste by letting multiple jobs securely share a single GPU, turning it into several right-sized virtual GPUs. This drastically lowers costs by maximizing your hardware value.
Remove the bottlenecks that slow down AI development: developer friction, complex config, and wasted compute.Get instant access to cloud and bare metal GPUs. We abstract away all the complexity of Kubernetes, YAML files, drivers, and networking, so your team gets one-click access to the compute they need through a simple-to-use UI. Set schedules to automatically start or stop jobs, eliminating off-hour waste and ensuring resources run only when needed.

Automate complex infrastructure management, from dynamic resource scaling and reproducible environments to high-speed data access.
Deploy multi-GPU clusters in minutes for immediate model training, while ensuring fair resource allocation and preventing bottlenecks as you scale.
Spin up production-ready environments in minutes, all while benefiting from continuous governance, optimization, and lifecycle automation.
Orchestrate your cloud infrastructure for best results and ROI from a user-friendly, single platform - for maximum performance.